Robots.txt
Robots.txt-filen er en af de vigtigste måder til, at fortælle søgemaskinerne, hvilke sider, sektioner og filer, de må tilgå på dit website. De fleste søgemaskiner understøtter den funktionalitet, som robots.txt tilbyder.

Hvad er Robots.txt?
Robots.txt er en fil der fortæller søgemaskiner (user-agents), hvor de kan og ikke kan gå hen på dit website. De største søgemaskiner, inklusiv Google og Bing, anerkender og respekterer anmodninger fra en robots.txt-fil.

Robots.txt er en relativ enkel fil, men samtidig også en af de filer, der er nemmest at lave rod i. Hvis bare et enkelt tegn står forkert, så kan det have fatale konsekvenser og ødelægge din SEO, ved utilsigtet, at blokere for Googles adgang til vigtigt indhold.
Primært viser filen alt at det indhold, som du ønsker at blokere fra søgemaskiner så som Google. En robots.txt-fil bliver også kaldt for en “Robots Exclusion Protocol” eller REP. På trods af ordet ekskludering i navnet, så dækker REP også mekanismer til inkludering.
Desværre er fejlkonfiguration i denne fil meget almindelig. I vores komplette guide til robots.txt vil du lære alt om, hvordan du bruger filen korrekt og i forhold til SEO.
Hvorfor er Robots.txt vigtig?
Faktisk har de fleste websites ikke brug for en robots.txt-fil. Dette skyldes at Google normalt selv kan finde og indeksere dine vigtigste sider. Derudover forsøger de selv at de-indeksere sider som ikke vigtige, eller som er duplikerede versioner af andre sider.
Når det er sagt, så er det altid en god idé at have en, da det giver dig mere kontrol over, hvilke sider, sektioner og filer, som søgemaskinerne har adgang til.
Der er 3 primære årsager til, at du vil bruge en robots.txt-fil.
Bloker ikke-offentlige ressourcer: De fleste websites har sider eller filer, som ikke bidrager til meget værdi i søgemaskinerne og derfor kan blokeres. Det kan f.eks. være en login-side, en privatlivspolitik, en PDF eller CMS-sider. Det er ikke alle sider og filer, hvor det er optimalt, at tilfældige brugere lande på og dem kan du blokere.
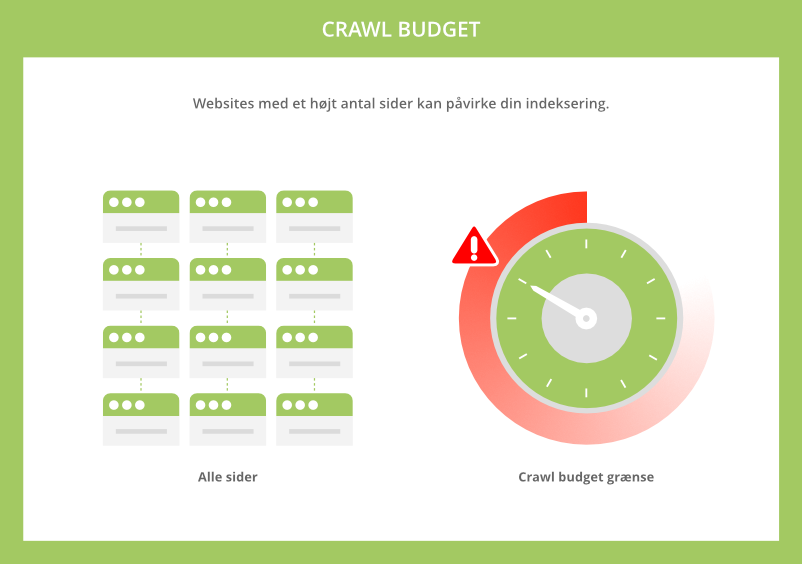
Maksimer crawl budget: Har du et website med rigtig mange sider, så kan det være svært, at få Google til at indeksere alle dine sider. I dette tilfælde kan du have problemer med dit crawl budget. Ved at blokere redundante eller ikke-vigtige sider, kan Googlebot dedikere tiden på, at crawle de sider som er vigtigst.
Undgå crawling af duplicate content: Har du f.eks. brugt produkttekster fra dine PDF-filer på HTML-sider, så kan det give problemer med duplicate content.
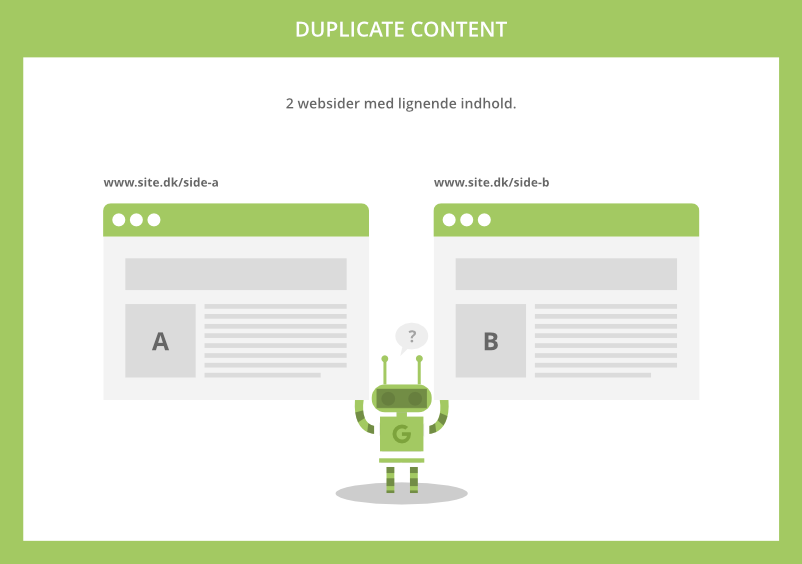
Det samme kan URL’er med parametre i forbindelse med din navigation. Her kan du bruge robots.txt-filen til, at blokere for søgemaskinernes adgang til problematiske filer og sider. Robots.txt kan med andre ord give instrukser til søgemaskinerne om, hvilke sider de ikke må crawle på dit website.
Bemærk dog at blokering igennem din robots.txt-fil, ikke afholder en webside fra at blive vist i Googles søgeresultater. Hvis du ønsker at ekskludere en side fra Google, så kan du istedet bruge meta-tagget “noindex”.
At forstå det grundlæggende foruden begrænsningerne ved robots.txt er helt essentiel, inden du opretter eller redigerer denne fil.
I Google Search Console kan du se, hvor mange sider du har indekseret i Google.
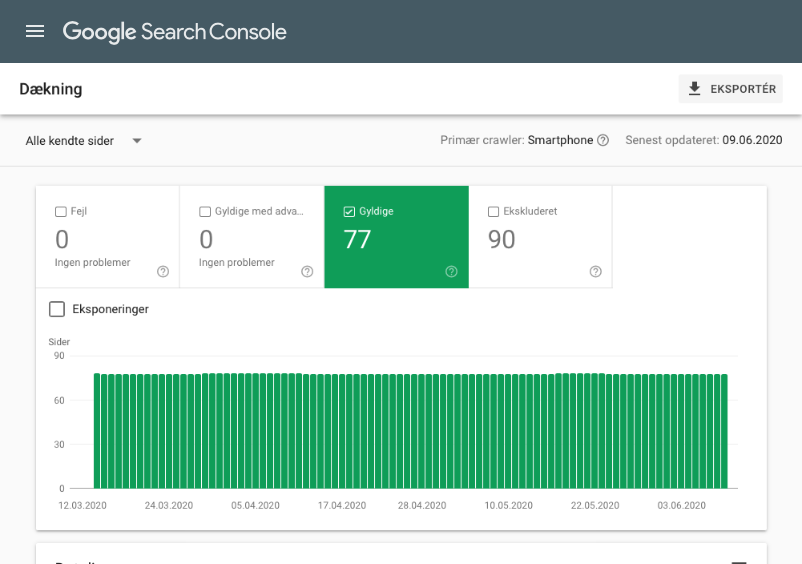
Hvis antallet matcher det antal sider som du vil have indekseret, så behøves du ikke at opsætte en robots.txt-fil. Er antallet derimod meget højere end forventet, så bør du få oprettet en robots.txt-fil på dit website.
Hvordan ser en robots.txt fil ud?
Her er et grundlæggende format for en robots.txt-fil:
User-agent: [1. bot-id] [direktiv 1] [direktiv 2]
User-agent: [2. bot-id] [direktiv 1] [direktiv 2]
Har du aldrig kigget i en af disse filer før, så kan det virke afskrækkende. Syntaksen som bruges er dog relativ enkel. Kort instruerer du bots (søgemaskiner) om, hvad de må og ikke må, ved at angive deres user-agent efterfulgt af direktiver.
Lad os kigge nærmere på disse 2 komponenter.
User-agents
Hver søgemaskine identificerer sig selv med en unik brugeragent (user-agent). Du kan angive brugerdefinerede instrukser for hver agent i din robots.txt-fil. Der findes hundredvis af user-agents.
Her er nogle du bør kende i forhold til SEO:
- Google: Googlebot
- Google Images: Googlebot-Image
- Bing: Bingbot
- Yahoo: Slurp
- DuckDuckGo: DuckDuckBot
- Baidu: Baiduspider
Bemærk: Der er forskel på små og store bogstaver i robots.txt.
Du kan også bruge (*) wildcard for at tildele direktiver til alle brugeragenter.
Så hvis du f.eks. ønskede at blokere alle søgemaskiner pånær Googlebot fra at crawle dit site, så ville du gøre dette med:
User-agent: * Disallow: / User-agent: Googlebot Allow: /
Din robots.txt-fil kan indeholde så mange user-agents og direktiver, som du ønsker.
Direktiver som du tildeler en specifik user-agent, vil ikke gøre sig gældende for de andre user-agents. Eneste undtagelse til den regel er, hvis du erklærer den samme brugeragent mere end én gang. I et sådan tilfælde kombineres alle direktiver.
Direktiver
Direktiver er regler, som du ønsker de deklarerede brugeragenter skal følge. Nedenfor kan du se de direktiver, som Google understøtter og deres funktionalitet.
Disallow
Brug disallow: når du vil blokere søgemaskinernes adgang, til filer eller sider under den specifikke sti.
Hvis du f.eks. vil blokere alle søgemaskinerne fra at få adgang til dit website og alle dens undersider, så kan du bruge følgende:
User-agent: * Disallow: /
Hvis du derimod ikke angiver en sti efter disallow-direktivet, så vil søgemaskinerne ignorere reglen og fortsat kunne tilgå alle sider og filer:
User-agent: * Disallow:
Hvis du vil blokere en enkelt undermappe, så kan du bruge følgende:
User-agent: * Disallow: /undermappe/
Hvis du vil blokere en specifik fil, så kan du bruge følgende:
User-agent: * Disallow: /dette-er-en-fil.pdf
Du kan også finde mere avancerede eksempler, som matcher URL-mønstre, under afsnittet robots.txt eksempler senere i guiden.
Allow
Brug allow: når du vil tillade søgemaskiner, at crawle en undermappe eller en side – også i en ellers ikke tilladt undermappe. Hvis du f.eks. vil blokere alle søgemaskiner fra din /wp-admin/ pånær en specifik fil, så kan du tilføje følgende i din robots.txt-fil:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Her vil søgemaskiner stadig have adgang til /wp-admin/admin-ajax.php filen. Både Google og Bing understøtter dette direktiv.
Hvis der uheldigvis opstår modstridende direktiver i din robots.txt-fil, så vil Google og Bing vælge direktivet med flest karakterer:
User-agent: * Disallow: /undermappe/ Allow: /undermappe
I dette tilfælde vil disallow-direktivet vinde med 12 vs. 11 karakterer. Og hvis begge direktiver har det samme antal karakterer, så vil det mindst restriktive direktiv vinde, som i dette tilfælde vil være allow-direktivet.
Denne regel er kun gældende for Google og Bing. Andre søgemaskiner vil altid lytte til det først-matchende-direktiv, som i ovenstående tilfælde vil være disallow-direktivet.
Sitemap
Brug sitemap: til at specificere lokationen på dit sitemap til søgemaskiner. Hvis ikke du er bekendt med sitemaps, så inkluderer de grundlæggende de sider, som du ønsker søgemaskinerne skal crawle og indeksere.
Hvis du vil specificere lokationen på et eller flere af dine sitemaps, så kan du tilføje følgende i din robots.txt-fil:
Sitemap: https://www.domain.dk/sitemap1.xml
Sitemap: https://www.domain.dk/sitemap2.xml User-agent: * Disallow: /ordliste Allow: /ordliste/tilladt-artikel
Husk altid at bruge den absolutte URL, når du angiver lokationen til sitemap(s).
Derudover er det ikke nødvendigt, at gentage dit sitemap-direktiv for hver user-agent. Du gør bedst i, at angive sitemap-direktiver i begyndelsen eller under brugeragenten (*) wildcard, for at tildele direktivet til alle søgemaskiner.
Ikke-understøttede direktiver
Der er også en række direktiver, som Google ikke understøtter, hvorfor de bliver ignoreret ved brug i din robots.txt-fil.
Noindex
Direktivet noindex: var officielt aldrig understøttet af Google. Formålet med dette direktiv var, at blokere en side eller fil fra søgeindeksering:
User-agent: Googlebot Noindex: /ordliste/
Hvis du vil blokere en side fra søgeindeksering, kan du istedet benytte meta-tagget “noindex” på den pågældende side. Er det en fil du ønsker at blokere, så kan du benytte en X-Robots-Tag-header med værdien “noindex”.
Crawl-delay
Direktivet crawl-delay: betød, at du kunne forsinke Googles gennemgang af dit website, angivet i sekunder. Så hvis du f.eks. ville forsinke Googlebot med 10 sekunder efter hver crawlhandling, så kunne du gøre dette således:
User-agent: Googlebot Crawl-delay: 10
Google understøtter ikke dette direktiv men det gør Bing og Yandex.
Du bør dog altid bruge dette direktiv med stor forsigtighed. Som udgangspunkt anbefaler vi aldrig, at begrænse søgemaskinerne fra at crawle sider. Specielt ikke hvis du har et stort website med tusindvis af sider.
Nofollow
Direktivet nofollow: understøttes heller ikke af Google. Her var formålet, at instruere søgemaskinerne om, ikke at følge links på sider eller filer under en specifik sti. Så hvis du ønskede at blokere Google fra, at følge alle links på ordliste-siden, så ville du bruge:
User-agent: Googlebot Nofollow: /ordliste/
Hvis du vil nofollow alle links på en side, så bør du benytte meta-tagget “nofollow” eller på filer, en X-Robots-Tag-header med værdien “nofollow”. Du kan også brug rel=”nofollow” på individuelle links. Som udgangspunkt anbefaler vi, kun at bruge nofollow på eksterne links til andre websider, som du ikke kan stå inde for.
Hvordan finder du din robots.txt fil?
Hvis du allerede har en robots.txt-fil, så vil den være at finde i roden af det domæne, som du ønsker at kontrollere søgemaskinernes crawling på.
Hvis det f.eks. er www.domain.dk, så skal filen være tilgængelig under www.domain.dk/robots.txt. Hvis det er domain.dk, så skal filen være tilgængelig under domain.dk/robots.txt.
Når du åbner filen skulle du gerne se en tom fil eller nogle få direktiver i stil med:
# Fuld adgang til alle søgemaskiner:
User-agent: * Disallow:
Du kan med fordel tilgå og redigere filen via et FTP-program.
Sådan opretter du en robots.txt fil
Hvis ikke du allerede har en robots.txt-fil, så kan du starte med, at oprette en tom txt-fil på din computer. Begynd nu at tilføje de ønskede direktiver. Hvis du f.eks. vil blokere søgemaskiner fra at crawle dit /cms/ underbibliotek så tilføj følgende:
User-agent: * Disallow: /cms/
Tilføj nu flere direktiver efter behov. Når du er færdig uploader du filen til roden af dit website, f.eks. via dit FTP-program. Husk altid at navngive filen “robots.txt”.
Hvis du vil kan du også benytte en robots.txt generator som denne. Fordelen ved at bruge et værktøj er, at det minimerer chancen for syntaks-fejl. Bare rolig, vi viser dig også hvordan du kan kontrollere dit robots.txt-fil for fejl senere i guiden.
I denne guide fra Google findes der også mere information og forskellige regler, som du kan bruge til at blokere bots fra at crawle forskellige sider på dit website.
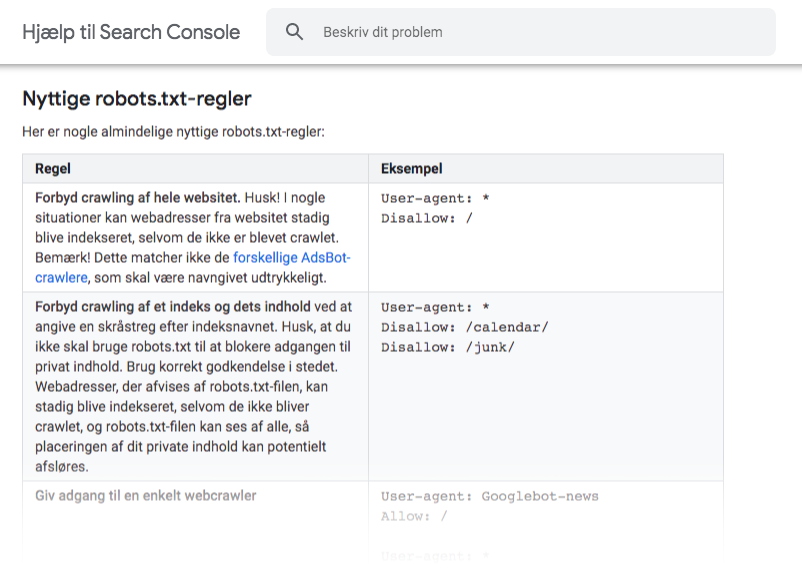
Sådan bruger du Robots.txt
Her er hvad du skal huske, for at undgå de mest almindelige fejl.
Brug en ny linje for hvert direktiv
Hvert direktiv og user-agent bør have sin egen linje, da det ellers kan forvirre søgemaskinerne:
User-agent: Googlebot Disallow: /undermappe/
Disallow: /undermappe-2/
Du kan også gruppere user-agents, som skal følge de samme direktiver:
User-agent: Googlebot
User-agent: Bingbot
Disallow: /undermappe/
Disallow: /undermappe-2/
I dette tilfælde blokeres både Google og Bing fra at crawle de 2 undermapper.
Robots.txt eksempler
Nedenfor har vi samlet en række direktiver, der er en tand mere avanceret. Eksemplerne er primært til inspiration.
kombiner direktiver med wildcards
Du kan ikke kun tildele direktiver til alle søgemaskiner med wildcards (*), du kan også matche forskellige URL-mønstre og dermed kombinere direktiver.
Hvis du f.eks. vil blokere alle søgemaskiner fra at crawle 3 produktkategori med parametre, så kunne du bruge følgende:
User-agent: * Disallow: /produkter/jakker?
Disallow: /produkter/jeans?
Disallow: /produkter/t-shirts?
Dette ville dog ikke være særlig effektivt, hvis du havde hundredevis af produktkategorier. En væsentlig bedre løsning ville være:
User-agent: * Disallow: /produkter/*?
Her blokerer du søgemaskinerne fra at crawle alle URL’er i undermappen /produkter/, som indeholder et spørgsmåltegn (?). Med andre ord alle produktkategorier med denne parameter.
Brug “$” til at specificere slutningen på en URL
Brug dollartegn ($) til at markere enden på en URL. Hvis du f.eks. vil blokere alle søgemaskiner fra at crawle dine PDF-filer, så kan du bruge følgende:
User-agent: * Disallow: /*.pdf$
Her kan søgemaskinerne ikke tilgå URL’er der ender på .pdf. Det betyder f.eks., at de ikke kan få adgang til filen /fil.pdf. De kan dog stadig få adgang til /fil.pdf?id=12221 fordi denne URL ikke ender på .pdf.
Vær specifik for at undgå utilsigtede fejl
Hvis du undlader at give specifikke instrukser, når du tildeler direktiver, så kan det resultere i katastrofale fejl, som kan have stor indflydelse på din SEO.
Lad os sige at du driver et website, hvor du sælger ydelser som fotograf. Her arbejder du på en ny sektion på dit website i undermappen /foto/.
Men fordi sektionen ikke er helt klar, så vælger du at blokere søgemaskinernes adgang til undermappen – og alt deri:
User-agent: * Disallow: /foto
Dette direktiv vil desværre også betyde, at alle sider og filer der begynder med “foto” bliver blokeret så som:
- /fotograf
- /fotoshoot
- /fotos
- /foto-priser
Denne fejl kan undgås ved, at afslutte direktivet med en skråstreg.
User-agent: * Disallow: /foto/
Bemærk også, at direktiver skelner imellem store og små bogstaver. I ovenstående eksempel vil /Foto/ derfor ikke blive blokeret.
Bloker URL’er med parametre
Hvis du har et website der benytter sig af filtrering og sortering, så skaber dette formentlig en masse URL’er med parametre. Dette kan både gå ud over dit crawl budget og skabe duplicate content, hvis ikke du blokerer søgemaskinernes adgang til dem.
Hvis du vil blokere alle URL’er med parametre, så kan du bruge følgende:
User-agent: * Disallow: /*?*
Dette vil blokere alle URL’er, som indeholder et spørgsmåltegn (?).
Brug kommentarer til at forklare din robots.txt-fil til mennesker
Kommentarer kan hjælpe udviklere og andre med, at forstå instrukserne i din robots.txt-fil. For at inkludere en kommentar, så starter du blot linjen med et hashtag (#).
# Dette instruerer Bing om ikke at crawle websitet User-agent: Bingbot Disallow: /
Crawlere ignorerer alle linjer der starter med et hashtag.
Brug en seperat robots.txt-fil for hvert subdomæne
Fordi robots.txt kun instruerer crawlere på subdomænet hvor filen er hostet, så er du nød til, at oprette en robots.txt-fil for hvert subdomæne.
Hvis dit primære website f.eks. er domain.dk, så kunne det være, at du havde en blog på blog.domain.dk. I dette tilfælde bør der ligge en robots.txt-fil i roden af hvert subdomæne.
kontroller din robots.txt-fil for fejl
Det er nemt at lave robots.txt-fejl og det kan resultere i katastrofale følger for din SEO. Det er derfor vigtigt, at du holder øje med dette og kontrollerer din robots.txt-fil for fejl, når du tilføjer eller ændrer direktiver.
En af måderne du kan kontrollere filen på, er igennem værktøjet Test af robots.txt i Search Console. Efter du har valgt dit website, så ser du muligvis nogle fejl, hvad de betyder og hvordan du kan rette dem.
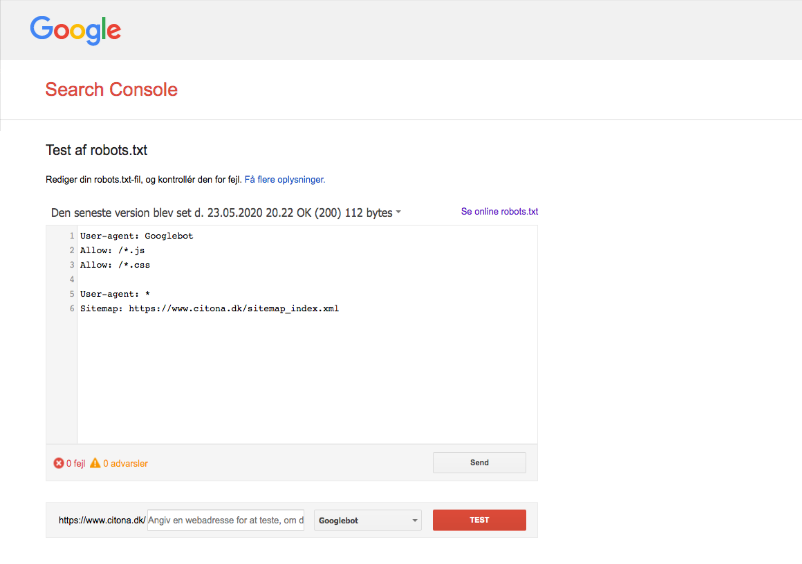
Fejl kan f.eks. være URL’er som er med i dit XML sitemap men som bliver blokeret af robots.txt. Eller hvis du har sider som er sat til noindex eller bliver omdirigeret, så må søgemaskinernes adgang til disse sider heller ikke blokeres.
Du kan også bruge værktøjet i Search Console til at teste, hvilke direktiver der blokerer indholdet i forhold til forskellige user-agents.
Indekseret på trods af blokering i robots.txt
Værktøjet kan også give dig en advarsel om, at noget indhold er blevet indekseret, selvom det bliver blokeret i robots.txt.
Hvis dit ønske at ekskludere dette indhold fra Googles søgeresultater, så er robots.txt ikke løsningen. Fjern istedet blokeringen i robots.txt filen og bloker for søgeindeksering med “noindex”, for at forhindre indholdet i at blive indekseret.
Teknisk SEO

Lær mere
Godt gået! Du har nu læst guiden "Robots.txt" og er sikkert blevet meget klogere. Du er klar til at kaste dig over den næste lektion.
Flere emner
Linkbuilding

User Experience

SEO værktøjer
